
2. Data Science
PROJECT MANAGEMENT
Tools of trade
Github for versioning.
- README in directories
- Trello/github
- /project – anal1 …
- /data – raw, unprocessed data
- /refererences – fastq files and human references
- /code – Javabased or compiled
- ~/bin – where executables go
- ~/scripts – where scripts go
- .bashrc settings for bash login
Early. Prototype the entire pipeline or analysis before cleaning up or creating elegant code.
Second. Create unit tests for each step
Third – only if it is going to be used. Remove hardcoding and add elegant solutions iteratively.
Waterfall vs Agile
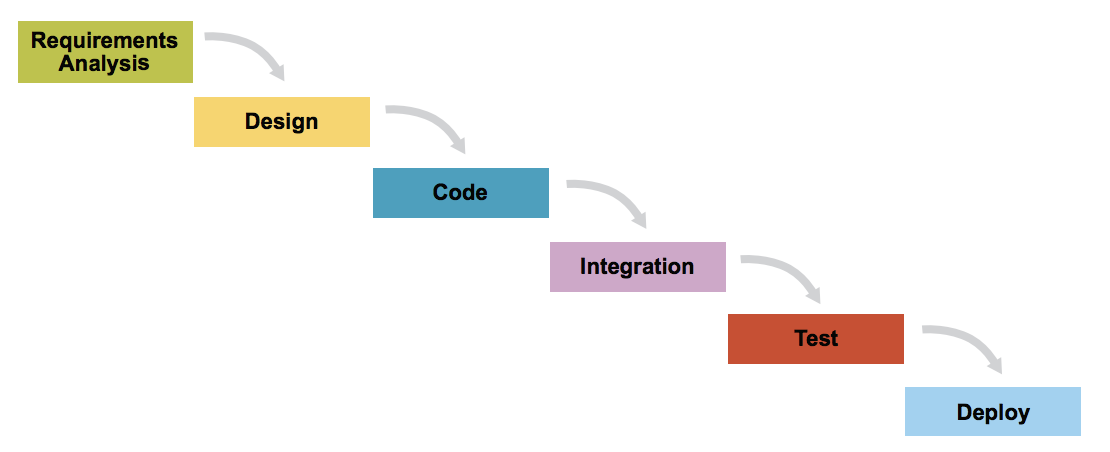
Waterfall. waterfall model is a relatively linear sequential design approach for certain areas of engineering design. In software development, it tends to be among the less iterative and flexible approaches, as progress flows in largely one direction (“downwards” like a waterfall) through the phases of conception, initiation, analysis, design, construction, testing, deployment and maintenance.
The waterfall development model originated in the manufacturing and construction industries; where the highly structured physical environments meant that design changes became prohibitively expensive much sooner in the development process. When first adopted for software development, there were no recognized alternatives for knowledge-based creative work.
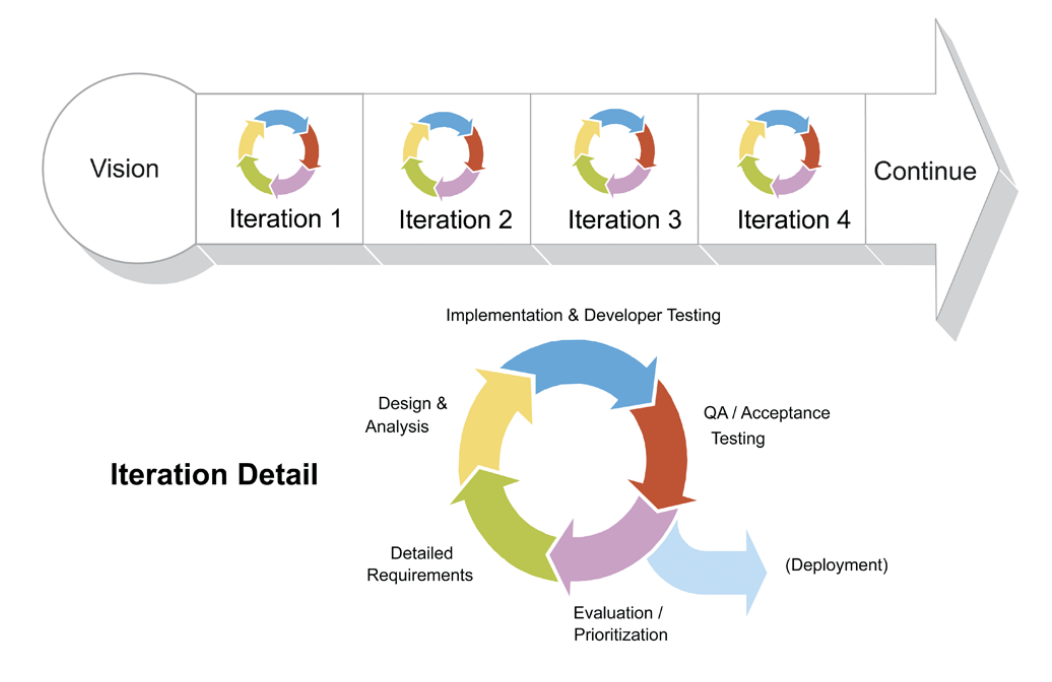
Agile software development is based on an incremental, iterative approach. Instead of in-depth planning at the beginning of the project, Agile methodologies are open to changing requirements over time and encourages constant feedback from the end-users. Cross-functional teams work on iterations of a product over a period of time, and this work is organized into a backlog that is prioritized based on business or customer value. The goal of each iteration is to produce a working product. In Agile methodologies, leadership encourages teamwork, accountability, and face-to-face communication. Business stakeholders and developers must work together to align the product with customer needs and company goals. Agile refers to any process that aligns with the concepts of the Agile Manifesto. In February 2001, 17 software developers met in Utah to discuss lightweight development methods. They published the Manifesto for Agile Software Development, which covered how they found “better ways of developing software by doing it and helping others do it” and included four values and 12 principles.
Waterfall
Agile
Manifesto for Agile Software Development
We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value: Individuals and interactions over processes and tools Working software over comprehensive documentation Customer collaboration over contract negotiation Responding to change over following a plan That is, while there is value in the items on the right, we value the items on the left more.
The fable of the Chicken and the Pig is used to illustrate the different levels of project stakeholders involved in a project. The basic fable runs:
-
- A Pig and a Chicken are walking down the road.
- The Chicken says: “Hey Pig, I was thinking we should open a restaurant!”
- Pig replies: “Hm, maybe, what would we call it?”
- The Chicken responds: “How about ‘ham-n-eggs’?”
- The Pig thinks for a moment and says: “No thanks. I’d be committed, but you’d only be involved.”
Sometimes, the story is presented as a riddle
-
- Question: In a bacon-and-egg breakfast, what’s the difference between the Chicken and the Pig?
- Answer: The Chicken is involved, but the Pig is committed!
In the last few years as agile has been rolled out to larger organizations, a new role has been identified. We call this the rooster. The rooster is very loud, disconnected from the work, and rarely knows what they are talking about.
Agile software development principles
The Manifesto for Agile Software Development is based on twelve principles:
- Customer satisfaction by early and continuous delivery of valuable software
- Welcome changing requirements, even in late development
- Working software is delivered frequently (weeks rather than months)
- Close, daily cooperation between business people and developers
- Projects are built around motivated individuals, who should be trusted
- A face-to-face conversation is the best form of communication (co-location)
- Working software is the primary measure of progress
- Sustainable development, able to maintain a constant pace
- Continuous attention to technical excellence and good design
- Simplicity—the art of maximizing the amount of work not done—is essential
- Best architectures, requirements, and designs emerge from self-organizing teams
- Regularly, the team reflects on how to become more effective, and adjusts accordingly
Iterative, incremental and evolutionary
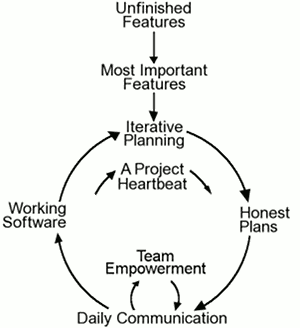
Most agile development methods break product development work into small increments that minimize the amount of up-front planning and design. Iterations, or sprints, are short time frames (timeboxes) that typically last from one to four weeks. Each iteration involves a cross-functional team working in all functions: planning, analysis, design, coding, unit testing, and acceptance testing. At the end of the iteration, a working product is demonstrated to stakeholders. This minimizes the overall risk and allows the product to adapt to changes quickly. An iteration might not add enough functionality to warrant a market release, but the goal is to have an available release (with minimal bugs) at the end of each iteration.[23] Multiple iterations might be required to release a product or new features.
Working software is the primary measure of progress.
Efficient and face-to-face communication
No matter which development method is followed, every team should include a customer representative (Product Owner in Scrum). This person is agreed by stakeholders to act on their behalf and makes a personal commitment to being available for developers to answer questions throughout the iteration. At the end of each iteration, stakeholders and the customer representative review progress and re-evaluate priorities with a view to optimizing the return on investment (ROI) and ensuring alignment with customer needs and company goals.
In agile software development, an information radiator is a (normally large) physical display located prominently near the development team, where passers-by can see it. It presents an up-to-date summary of the product development status. A build light indicator may also be used to inform a team about the current status of their product development.
Very short feedback loop and adaptation cycle
A common characteristic in agile software development is the daily stand-up (also known as the daily scrum). In a brief session, team members report to each other what they did the previous day toward their team’s iteration goal, what they intend to do today toward the goal, and any roadblocks or impediments they can see to the goal.[26]
Quality focus. Specific tools and techniques, such as continuous integration, automated unit testing, pair programming, test-driven development, design patterns, behavior-driven development, domain-driven design, code refactoring, and other techniques are often used to improve quality and enhance product development agility.[27] The idea is that the quality is built into the software. [28]
Scrum
Differences and Similarities Between Agile and Scrum
While Agile and Scrum follow the same system, there are some differences when comparing Scrum vs Agile. Agile describes a set of principles in the Agile Manifesto for building software through iterative development. On the other hand, Scrum is a specific set of rules to follow when practicing Agile software development. Agile is the philosophy and Scrum is the methodology to implement the Agile philosophy.
Because Scrum is one way to implement Agile, they both share many similarities. They both focus on delivering software early and often, are iterative processes, and accommodate change. They also encourage transparency and continuous improvement.
Adapted from Michael James and Luke Walter for CollabNet, Inc
Product Owner.
- Single person responsible for maximizing the return on investment (ROI) of the development effort
- Responsible for product vision
- Constantly re-prioritizes the Product Backlog, adjusting any longterm expectations such as release plans
- Final arbiter of requirements questions • Decides whether to release • Decides whether to continue development
- Considers stakeholder interests
- May contribute as a team member
- Has a leadership role
Scrum Master
- Works with the organization to make Scrum possible •
- Ensures Scrum is understood and enacted
- Creates an environment conducive to team self-organization •
- Shields the team from external interference and distractions to keep it in group flow (a.k.a. the zone) •
- Promotes improved engineering practices • Has no management authority over the team •
- Helps resolve impediments •
- Has a leadership role
Sprint Planning Meeting. At the beginning of each Sprint, the Product Owner and team hold a Sprint Planning Meeting to negotiate which Product Backlog Items they will attempt to convert to the working product during the Sprint. The Product Owner is responsible for declaring which items are the most important to the business. The Development Team is responsible for selecting the amount of work they feel they can implement without accruing technical debt. The team “pulls” work from the Product Backlog to the Sprint Backlog.
Daily Scrum and Sprint methods Every day at the same time and place, the Scrum Development Team members spend a total of 15 minutes inspecting their progress toward the Sprint goal, and creating a plan for the day. Team members share with each other what they did the previous day to help meet the Sprint goal, what they’ll do today, and what impediments they face.1
Extreme programming (XP)
Extreme Programming (XP) is an agile software development framework that aims to produce higher quality software and higher quality of life for the development team. XP is the most specific of the agile frameworks regarding appropriate engineering practices for software development.
The five values of XP are communication, simplicity, feedback, courage, and respect and are described in more detail below.
Communication. Software development is inherently a team sport that relies on communication to transfer knowledge from one team member to everyone else on the team. XP stresses the importance of the appropriate kind of communication – face to face discussion with the aid of a whiteboard or another drawing mechanism.
Simplicity. Simplicity means “what is the simplest thing that will work?” The purpose of this is to avoid waste and do only absolutely necessary things such as keep the design of the system as simple as possible so that it is easier to maintain, support, and revise. Simplicity also means address only the requirements that you know about; don’t try to predict the future.
Feedback. Through constant feedback about their previous efforts, teams can identify areas for improvement and revise their practices. Feedback also supports simple design. Your team builds something, gathers feedback on your design and implementation, and then adjust your product going forward.
Courage. KCourage as “effective action in the face of fear” (Extreme Programming Explained P. 20). This definition shows a preference for action based on other principles so that the results aren’t harmful to the team. You need courage to raise organizational issues that reduce your team’s effectiveness. You need courage to stop doing something that doesn’t work and try something else. You need courage to accept and act on feedback, even when it’s difficult to accept.
Respect. The members of your team need to respect each other in order to communicate with each other, provide and accept feedback that honors your relationship, and to work together to identify simple designs and solutions.
Whole Team. A cross functional group of people with the necessary roles for a product form a single team. This means people with a need as well as all the people who play some part in satisfying that need all work together on a daily basis to accomplish a specific outcome.
Informative Workspace. Set up your team space to facilitate face to face communication, allow people to have some privacy when they need it, and make the work of the team transparent to each other and to interested parties outside the team. Utilize Information Radiators to actively communicate up-to-date information.
Pair Programming. Pair Programming means all production software is developed by two people sitting at the same machine. The idea behind this practice is that two brains and four eyes are better than one brain and two eyes. You effectively get a continuous code review and quicker response to nagging problems that may stop one person dead in their tracks.
Teams that have used pair programming have found that it improves quality and does not actually take twice as long because they are able to work through problems quicker and they stay more focused on the task at hand, thereby creating less code to accomplish the same thing.
Kanban
Kanban is a scheduling system for lean manufacturing and just-in-time manufacturing (JIT). Taiichi Ohno, an industrial engineer at Toyota, developed kanban to improve manufacturing efficiency. Kanban is one method to achieve JIT.[3] The system takes its name from the cards that track production within a factory. For many in the automotive sector Kanban is known as “Toyota nameplate system” and as such, some other automakers won’t use the term Kanban.
DATABASES
A database is an organized collection of data at its simplest level. Data is usually organized by rows or tables that contain compartmentalized sets of data. Examples could include addresses, bank transactions, medical records, and just about anything you can think about. Arguably, a database could be a simple textfile, an Excel workbook, or a set of tables within a database management system. Popular database options including MySQL, PostgreSQL, Microsoft Access, Microsoft SQL, and Oracle are relational. They use SQL (Structured Query Language), which is a programming language just for managing data in a relational database. Non-relational databases, by contrast, do not have a strict column and row schema. They are viewed by proponents as “more flexible” and are increasingly used by organizations like Facebook, Google, and the NSA for big data situations like bioinformatics
History
The introduction of the term database coincided with the availability of direct-access storage (disks and drums) from the mid-1960s onwards. The Oxford English Dictionary cites a 1962 report by the System Development Corporation of California as the first to use the term “database” in a specific technical sense.
Modern databases are often built as Relational Databases, as outlined in the 1970 article by Dr. EF Codd “A Relational Model o fData for Large Shared Data Banks”. In this paper, he described a new system for storing and working with large databases. Instead of records being stored in some sort of linked list of free-form records as in CODASYL, Codd’s idea was to use a “table” of fixed-length records, with each table used for a different type of entity. A linked-list system would be very inefficient when storing “sparse” databases where some of the data for any one record could be left empty. The relational model solved this by splitting the data into a series of normalized tables (or relations), with optional elements being moved out of the main table to where they would take up room only if needed. Data may be freely inserted, deleted and edited in these tables, with the DBMS doing whatever maintenance needed to present a table view to the application/user.
Linking the information back together is the key to this system. In the relational model, some bit of information was used as a “key”, uniquely defining a particular record. When information was being collected about a user, information stored in the optional tables would be found by searching for this key. For instance, if the login name of a user is unique, addresses and phone numbers for that user would be recorded with the login name as its key. This simple “re-linking” of related data back into a single collection is something that traditional computer languages are not designed for.
Codd’s paper was picked up by two people at Berkeley, Eugene Wong, and Michael Stonebraker. They started a project known as INGRES using funding that had already been allocated for a geographical database project and student programmers to produce code.IBM started building the first database based on this model, and then in 1979 Oracle built Relational Technology began commercializing the first modern database. The impact of Oracle on modern computing in the workforce is often underestimated, but in fact, IBM and Oracle developed many of the tools that organized the foundational data within many industries. Larry Ellison’s Oracle Database started from a different chain, based on IBM’s papers on System R. The dominance of Oracle began when they beat IBM to market in 1979.
The 1980’s saw the emergence of desktop computing, empowering users with Lotus 1-2-3 and dBase – two tools that remained dominant through 1990s. The 90s also saw a rise in object-oriented programming and growth in how data in various databases were handled. Programmers and designers began to treat the data in their databases as objects. That is to say that if a person’s data were in a database, that person’s attributes, such as their address, phone number, and age, were now considered to belong to that person instead of being extraneous data. This allows for relations between data to be related to objects and their attributes and not to individual fields. Examples include: Name.address would give the address within the Name object.
In the 2000’s the rise of XML and later JSON documents occurred. Also began the rise of no-SQL databases (non-relational) which were very quick, and leveraged cheap data storage.
Tables
A table in a database is a collection of rows and columns. A table has defined the number of columns.
It can have any number of rows. The rows can be identified by one or more values within the column subset, though the uniquely identifying column is recommended – termed a UID. A specific choice of columns which uniquely identify rows is called the primary key. Viewsalso function as relational tables, but their content changes as the table data changes.Rows
A row contains data pertaining to a single item or record in a table – Rows are also known as records or tuples. This term tuple we see used in many programming languages such as Python.
Columns
A column contains data representing a specific feature of the data, and can also be described as fields or attributes.
Databases typically are founded with a few core functions or capabilities. One can create an entry, read an entry, update an entry, or delete an entry. The acronym is CRUD.
Database management system (DBMS)
A system that interacts users, software or other parts of the database, allowing viewing, editing, and analyzing data within the database.
CRUDdy Databases
The acronym CRUD refers to all of the major functions that are implemented in relational database applications. Each letter in the acronym can map to a standard Structured Query Language (SQL) statement, Hypertext Transfer Protocol (HTTP) method (this is typically used to build RESTful APIs):
| Operation | SQL | HTTP |
|---|---|---|
| Create | INSERT | PUT / POST |
| Read (Retrieve) | SELECT | GET |
| Update (Modify) | UPDATE | PUT / POST / PATCH |
| Delete (Destroy) | DELETE | DELETE |
The comparison of the database-oriented CRUD operations to the HTTP methods has some flaws. Strictly speaking, both PUT and POST can create resources; the key difference is that POST leaves it up to the server to decide at what URI to make the new resource available, while PUT dictates what URI to use; URIs as a concept do not align neatly with CRUD. The significant point about PUT is that it will replace whatever resource the URI was previously referring to with a brand new version, hence the PUT method being listed for Update as well. PUT is a ‘replace’ operation, which one could argue is not ‘update’.
In computer programming, create, read, update, and delete (CRUD) are the four basic functions of databases. Think of it as building a table.
SQL
SQL (Structured Query Language) is a computer language aimed to store, manipulate, and query data stored in relational databases. The first incarnation of SQL appeared in 1974, when a group in IBM developed the first prototype of a relational database. The first commercial relational database was released by Relational Software (later becoming Oracle).
Read/Select:
SELECT column-names FROM table-name WHERE condition ORDER BY sort-order
Example:
SELECT FirstName, LastName, City, Country FROM Customer WHERE City = 'Paris' ORDER BY LastName
Insert/Create
INSERT table-name (column-names) VALUES (column-values)
Example
INSERT Supplier (Name, ContactName, City, Country)
VALUES ('Oxford Trading', 'Ian Smith', 'Oxford', 'UK')
Update
UPDATE table-name SET column-name = column-value WHERE condition
Example
UPDATE OrderItem SET Quantity = 2 WHERE Id = 388
Delete
DELETE table-name WHERE condition
Example:
DELETE Customer WHERE Email = 'alex@gmail.com'
noSQL
NoSQL (referring to “non SQL” or “non-relational”) databases provide a mechanism for storage and retrieval of data that is modeled typically as key:value, and are document stores. JSONs are great examples. NoSQL databases are increasingly used in big data and real-time web applications. NoSQL systems are also sometimes called “Not only SQL” to emphasize that they may support SQL-like query languages, or sit alongside SQL database in a polyglot persistence architecture. Motivations for this approach include: simplicity of design, simpler “horizontal” scaling to clusters of machines (which is a problem for relational databases),and finer control over availability. The data structures used by NoSQL databases (e.g. key-value, wide column, graph, or document) are different from those used by default in relational databases, making some operations faster in NoSQL. The particular suitability of a given NoSQL database depends on the problem it must solve. Sometimes the data structures used by NoSQL databases are also viewed as “more flexible” than relational database tables.
A critical key is that they do not natively allowing joining.
ACID
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties of database transactions intended to guarantee validity even in the event of errors, power failures, etc. In the context of databases, a sequence of database operations that satisfies the ACID properties (and these can be perceived as a single logical operation on the data) is called a transaction. For example, a transfer of funds from one bank account to another, even involving multiple changes such as debiting one account and crediting another, is a single transaction.
Normalization
As needs change over time, a database will undergo frequent updates to its table and column layout. Redundant data can often occur and cause multiple problems:
- inefficient – the database engine will need to process more data for each query or update
- bloated – storage requirements increase due to redundant data
- errors – redundant data must be manually inputted, which is error-prone
Normalization is the formal term for the process of eliminating redundant data from database tables.
Joins
A SQL Join statement is used to combine data or rows from two or more tables based on a common field between them. Different types of Joins are:
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL JOIN
Joins in R
Referring back to R, dplyr is a great tool for joining two tables.
How would we join? First Load in data:
samples <- read.csv('sample_info.csv',header = TRUE, sep = ",", quote = "\"", dec = ".", fill = TRUE, row.names = 1)
genes <- read.csv('expression_results.csv',header = TRUE, sep = ",", quote = "\"", dec = ".", fill = TRUE, row.names = 1)
Lets get sum summary level information. What and how does this work?
genesummary<-data.frame(lapply( genes , function(x) rbind( mean = mean(x) , sd = sd(x) , median = median(x) , minimum = min(x) , maximum = max(x) , s.size = length(x) ) ))
Lets manipulate the dataframe:
genesummary_t=data.frame(t(genesummary))
Lets subset the dataframe:
filteredsamples <- subset(genesummary_t, sd < 1000 & maximum < 200000)
Lets create a common column to join on:
filteredsamples$names=rownames(filteredsamples) samples$names=rownames(samples)
Lets join:
pen_samples<-inner_join(samples,filteredsamples,by = "names")
Content sources include https://www.wikipedia.org/ and are available following Commons sharing.
GPL is a copyleft license essentially making it impossible to use code if one isn’t going to distribute it using the same license.
For this course, we will generally use the MIT License.
Permissive
BSD License
The BSD license is a simple license that merely requires that all code licensed under the BSD license be licensed under the BSD license if redistributed in source code format. BSD (unlike some other licenses) does not require that source code be distributed at all. “here’s the source code, do whatever you want with it, but if you have problems, it’s your problem”
MIT
Conditions only requiring preservation of copyright and license notices. Licensed works, modifications, and larger works may be distributed under different terms and without source code.
Copyleft
Apache License 2.0
Contributors provide an express grant of patent rights. Licensed works, modifications, and larger works may be distributed under different terms and without source code.
GNU Family
You are allowed to use, redistribute and change the software, but any changes you make must also be licensed under the GPL with different flavors.
GNU GPLv3
Permissions of this strong license are conditioned on making available complete source code of licensed works and modifications, which include larger works using a licensed work, under the same license. Copyright and license notices must be preserved. Contributors provide an express grant of patent rights. Same license required.
GNU LGPL v3
Permissions of this copyleft license are conditioned on making available complete source code of licensed works and modifications under the same license or the GNU GPLv3. Copyright and license notices must be preserved. Contributors provide an express grant of patent rights. However, a larger work using the licensed work through interfaces provided by the licensed work may be distributed under different terms and without source code for the larger work.
GNU AGPLv3
Permissions of this strongest copyleft license are conditioned on making available complete source code of licensed works and modifications, which include larger works using a licensed work, under the same license. Copyright and license notices must be preserved. Contributors provide an express grant of patent rights. When a modified version is used to provide a service over a network, the complete source code of the modified version must be made available. Requires same license, statement of changes
MIT LICENSE
MIT License Copyright (c) [year] [fullname] Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.